
Got Hash Tables?
When you first start learning computer science, it can feel like stepping out into another world. You’re seeing things — ideas, concepts, data structures — which you’ve never encountered before!
I think learning computer science makes you no less adventurous than the first Europeans to explore Massachusetts on the Mayflower; or what about those to first step on the moon in 1969?
One thing’s for sure: whether you’re exploring new ideas or new worlds — you’re going to meet new terms.
In this article I intend to help you learn about a computer science concept that (used to be) about as foreign to me as the kinds of mirchi in my mother’s traditional Pakistani cuisine: hash tables!
Learning Objectives
I intend that by the end of this article, you will better understand and be able to answer the following questions:
- Why Would I Ever Need to Use a Hash Table?
- How do Hash Tables work?
- What is a Hash Collision?
- What are the Different Resolutions to Hash Collisions?
- What will a Hash Table allow me to do in programs?
Why Would I Ever Need to Use a Hash Table?
To start with, I realize that learning about hash tables can seem pretty boring — after all, if it won’t help improve my software, why should I even bother?
So let’s begin by me telling you a scenario that shows just how useful this data structure can be — and you have no doubt experienced this before in your own life!
Think about the last time you made a phone call to a loved one. The year is 2020 — did you really dial their phone number to make the call, or simply use the Contacts app on your device? My guess is door number two.
Most of us have been making phone calls all our lives, and have at one point or another relied on the help of either the Contacts app (or its older equivalent, the analog phonebook) when we needed to call someone, but didn’t know their number. The reason this is important is because if you can understand how a phonebook works, you can understand how a hash table works, and how it will help you in solving real problems more efficiently in your programs!
The Problem: Storing and Retrieving Data
Phonebooks may seem pretty simple, but have we ever actually stopped to wonder just how useful they are? As of 2014 there are more phone numbers on this planet than there are humans (“There are now more gadgets on Earth than people”, CNET). That means every phone call you make to one other person is a selection of one unique item, from a dataset of billions of items!
Now let’s say you’re the head of the New Haven District Telephone Company — the year is 1878 (“The First Telephone Directory…”, HistoryofInformation.com). You’re on the verge of inventing the first phonebook. Just how many of those numbers do you want in your phonebook? Obviously the more the better — but how will you structure that data, such that storing and retrieving specific numbers is easy for your users?
The Problem with Lists
I know you’re not really a phonebook writer from 1878. You’re someone trying to learn CS, right? So let’s try and figure how to store this dataset, trying to use some common data structures you’ve undoubtedly heard of already: arrays and linked lists.
First question: do we even know what data we’re storing? Remember each single item in this data structure, actually contains two components: the name of a person and their phone number.
Another thing to consider: we don’t know how large the number of entries we’ll be storing in this data structure, because the number of SIM cards is always increasing. So that means there’s already a problem with using static arrays, isn’t it?
Okay, let’s go with linked lists, because they can dynamically resize, and will be less expensive in terms of memory than dynamic arrays. There’s still another problem that arises though, when it comes time to retrieve data from this structure. Pay attention to the language here, I promise it will make more sense in a bit!
The reason we use phone books is because we don’t like memorizing phone numbers. As humans, all we care about is remembering a person’s name, and using that as a way to unlock their phone number from the data structure. That being said, the person’s name is kind of like a key. When retrieving a number, our problem is this: out of many items, how will we pick out the one phone number, or value, that’s relevant to us, when all we know is a person’s name?
If we’re using a linked list, can you guess how we’ll search through all the information? A traversal!
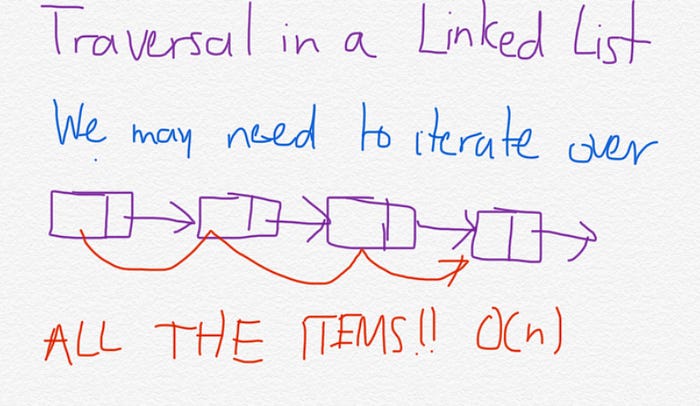
Using this approach quickly becomes cumbersome; because we have to iterate over every single item in the list, checking if the name stored with each item matches with the name we have been given, and only if we find a match can we return the number associated with that name. Think of it like this: would you ever look for a phone number for a person by opening up to the first page, scanning through all the names, and then turning (potentially) thousands of pages over until you found the name you were interested in?
In fact, this is not just a problem with linked lists, which are a data structure; but it’s a fundamental problem with lists, the abstract data type that both arrays and linked lists based on. By the way, an abstract data type is just a fancy word for something that defines the interface of a data structure — like the methods in a class, for example.
Anyway, if we want to solve our problem of storing and retrieving data more efficiently, we need to learn about new abstract data type (which will lay the groundwork for our understanding of the hash tables as a data structure): the map!
How Do Hash Tables Work?
The Map ADT
At a high level, a map is any type of data structure in which two sets of data are associated to each other in unique pairs. Typically you’ll see one of these sets being called the keys, and the others being labelled the values. Alternatively, you could abbreviate these pairs to just “(k,v)” (Vaidehi Joshi, “Taking Hash Tables Off The Shelf”).
Essentially, what the map allows us to do is lookup any value, given we know its key. So for our phonebook example, our key value pairs would look like this:
(person’s name, person’s phone number)
Okay great! But what’s so special about this interface?
The Parts of a Hash Table
To find out, let’s finally take a look under the hood of the hash table!
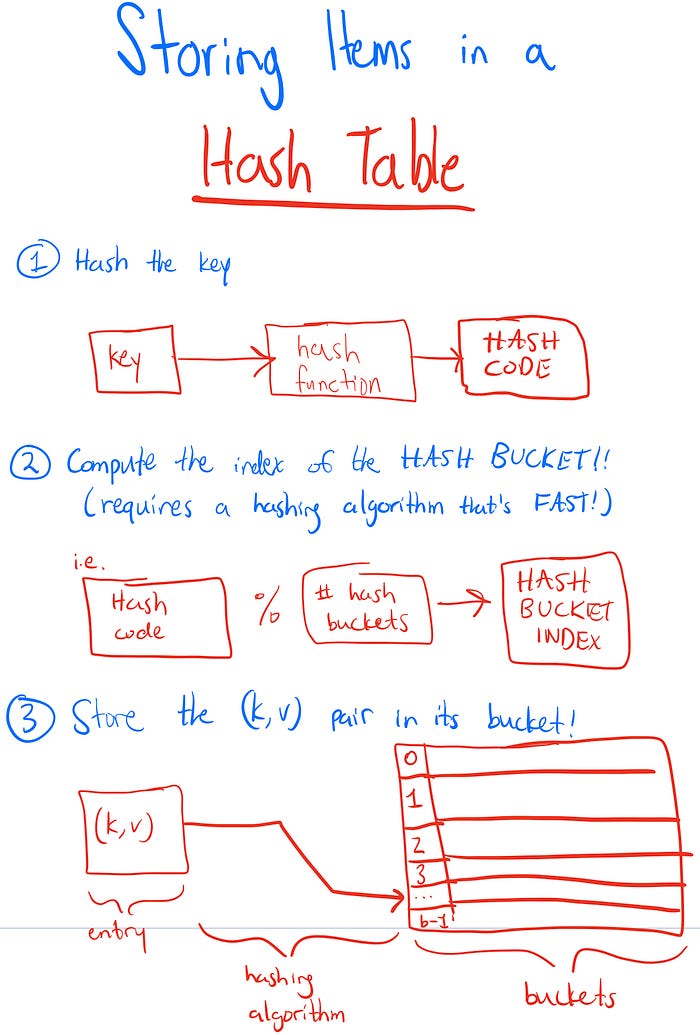
Basically, a hash table is type of map that is implemented using two essential components:
- An array, used to store the entries from our dataset (the key value pairs)
- And a hash function, which is used to map specific keys and values together. Given a key as input, a hash function outputs the value that goes with that key.
Implementation of a Hash Table
The main advantage of the hash table is speed. We may be using an array to store our key value pairs, but thanks to the hash function we can avoid traversing through the array indices (also called the hash buckets) to find an item — we simply input the key into our hashing algorithm, as we use the output to go straight to the hash bucket where our value is located!
The diagrams below will go further into how we store/retrieve data from a hash table:
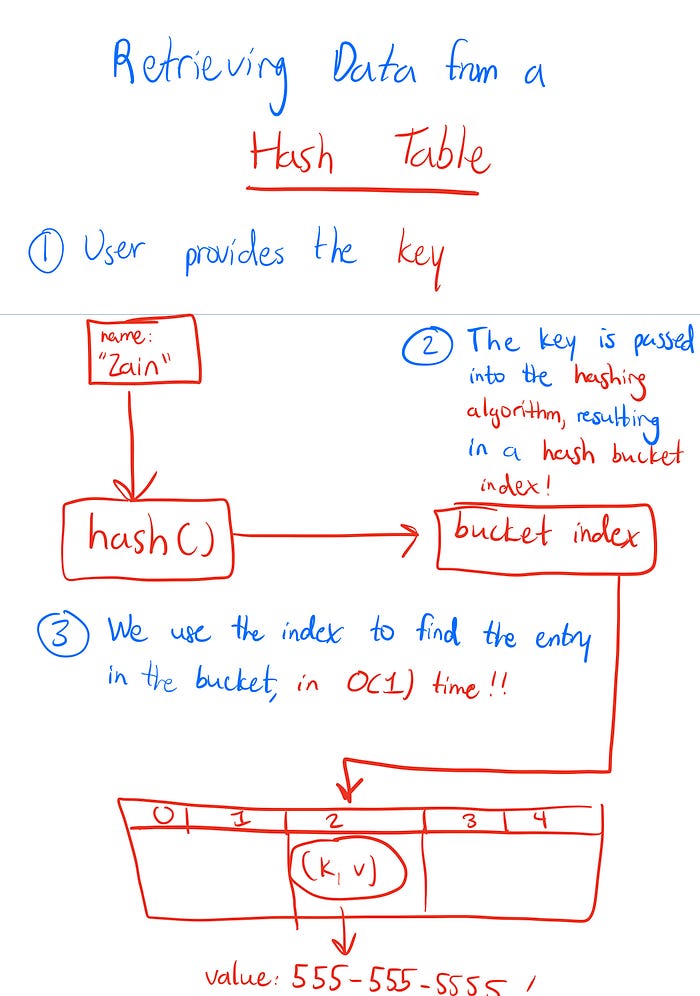
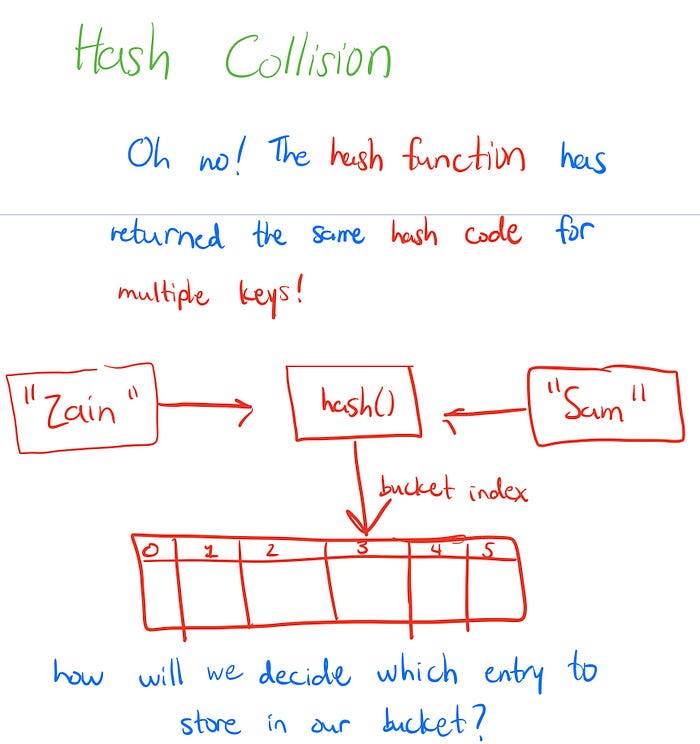
What is a Hash Collision?
So the hash table should be able to handle constant time lookups, right? But what about size? It can grow dynamically, right? Are we able to grow our hash table indefinitely, or is that just too good to be true?
Time for some clarification: a hash table on its own very quickly comes into an issue. We can’t really map all our keys to their own unique hash code value — we want to be able to store a possibly infinite number of items after all, yet we only have a finite number of possible hashcode values (Alan Davis, Make School’s Hash Table slides) that can come out of our hash function (the same number of possible numbers you can store in an unsigned integer, in whatever programming language you’re working with).
To summarize, a hash collision is simply when we have multiple keys in the hash table mapping to one hash code. If it doesn’t yet seem clear why this is a problem, let’s go back to our phone book: what would you think if you opened up the contact information for someone named “Mom” on your iPhone, and two different phone numbers showed up? Your address book is confused! Somewhere it has mapped the you “Mom” lookup to the phone numbers of more than just one person — how would you know which is the number you’re really looking for?
What are the Different Resolutions to Hash Collisions?
Resolution #1: Linear Probing
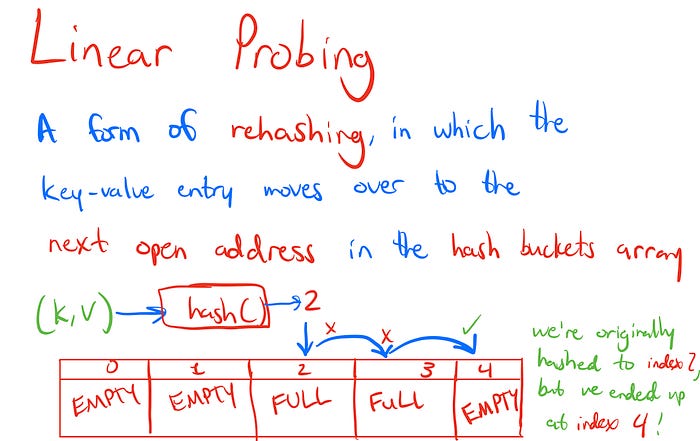
In this method when we have a hash collision, whichever value already occupies a memory slot in our array, stays where it is. Then, the other value that was supposed to go to into that index, as determined by our equation above relating the hash function and the index), will simply move to another memory address in the array that’s open. Another popular name for this resolution method is called open addressing.
Resolution #2: Separate Chaining
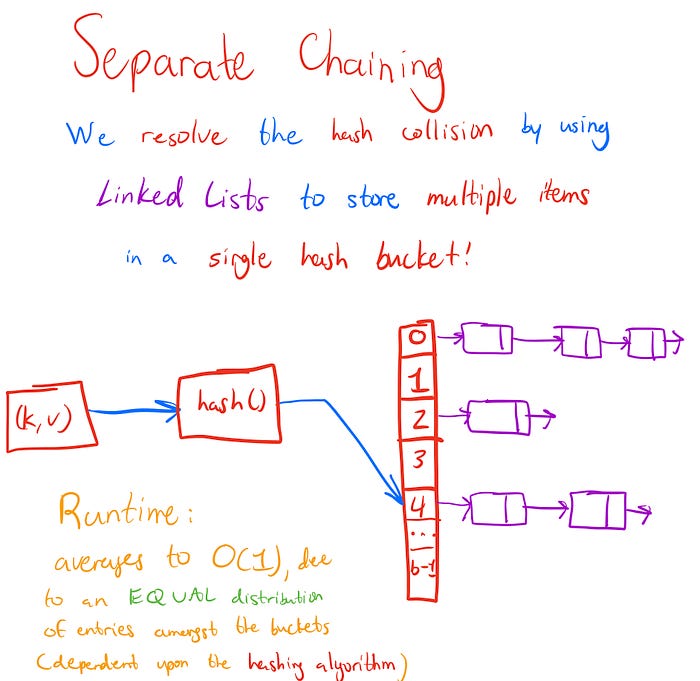
In this method, we use linked lists in order to let all keys that map to the same hash code, be able to store their associated values at the same index in our hash table array. How so? By not storing any items in the array at all; instead, the only items that will be stored in the array are linked lists, another data structure that can grow dynamically in size. That way, when we need to store a value at an index in the array, we go to the linked list object in the array index and add the new value not to the array itself, but as a new node to the linked list at that index. Likewise when we have another value to add that’s mapped to that array index, we simply add it to the linked list at that index, as another node.
Resolutions Compared
Both of these methods have their drawbacks. They also both have their advantages, so if you have a good understanding of each you will be better off in implementing them so as to maximize benefits to your program’s users!
Linear Probing and Space Complexity
Linear probing may seem like the simpler of these two approaches.
However ease of implementation may be more trouble than it’s worth: because in this resolution method, we now have limited the size of the hash table to the size of the array we are using. The hash table cannot have more values than it has slots in the array, otherwise we will have nowhere to store those values! This resolution is best left to implement when we have a good handle on how many items we’ll have in our dataset, before the hash table is even made.
Separate Chaining and Time Complexity
Remember the runtime complexity of searching through a linked list? This is where that becomes important; because if we use separate chaining, we have to realize that simply indexing into a hash bucket does not locate our key value entry! It locates a linked lists of many entries, and we need to traverse through them in order to find the entry we’re looking for — or if the entry’s not present, we need to traverse through all of them!
The complexity of this operation is no longer O(1); and is instead described using a variable with a special name: the load factor. The load factor describes the average number of entries that are located in a single bucket we may traverse through. If that sounds convoluted, don’t worry: we simply take the total number of entries in the hash table, and divide by the number of hash buckets!
More good news: there is still a way to maintain a reasonable lookup time complexity with chaining, and it lies in the hashing algorithm. A good hash function will rarely cause hash collisions to begin with, and even if it does it should equally distribute them among the output space (aka our hash buckets). An unequal distribution of hash table entries leads to clustering, which is when we may have most of our entries stored in only a few buckets — and this needs to be avoided at all costs!
Thankfully there are already great hash functions out there for us to use, that don’t do this. Therefore when we have a well-spaced hash table, (the opposite of clustering), we can reliably say our lookup time will not vary too much on average — leading to an amortized runtime complexity that’s still O(1).
What will a Hash Table allow me to do in programs?
Okay, so we’ve just gone over a ton of information related to hash tables. Can you think of anywhere you might actually apply this data structure?
Time for some examples!!
Limitations in Ordering
Let me tell where hash tables aren’t useful: storing a and retrieving operations for an ordered dataset. The key-value entries don’t have any relationship to each one another. Think of it this way: when was the last time you were ever interested in finding the last phone number listed in the phonebook?
I’m guessing that it’s never happened; because when we lookup phone numbers, it’s because we’re interested in finding the number related to a specific person’s name, that’s associated to that number.
Advantages in Searching
Does this analogy show a glaring problem with hash tables? I suggest you think again; even though hash tables don’t allow us to lookup by order, such as through a numerc index like an array, that’s not necessarily a problem. Rather, it just means that you and I as the programmer need to make sure we apply the hash table where it best fits.
SQL
Now consider this: how did Google show you the URL address of this page? Or how about that birthday present you found for your friend on Amazon? What about that movie you watched last Friday night on Netflix?
What feature do all these applications depend on? Search!
What data structure have we just learned, that makes search super fast? Hash tables!
Think about that the next time you’re programming the back-end database for a website or mobile application — if you’re using SQL, the entire reason your website serves data to your users to render your landing page, show search results, anything sends an HTTP GET request to the backend, and do it fast — is in part due to a hash table working under the hood.
Resources and Wrap-Up
Congratulations my fellow explorer! Hopefully now you have a better understanding of how hash tables work. If there are any topics that were unclear, feel free to check out these other great links to reinforce your knowledge of this powerful data structure. Happy coding!
- Watch Harvard CS50’s hash table video explanation
- Read this great article by Vaidehi Joshi’s on hash tables
- Use the interactive hash table found on VisuAlgo
- Read Vaidehi Joshi’s explanation of hash tables
- Look over Make School’s slide deck on hash tables
- Ready to see it in action? Below is one example of how to implement a Hash Table class, using Python. It includes only the constructor (the __init__ method), the hashing algorithm (the _bucket_index method), and methods for storing data (the set method) and getting data (the get method) from the hash table. For a full implementation, please check out my GitHub repository.










